ICCV 2025(IEEE/CVF International Conference on Computer Vision)将于2025年10月19日至23日在美国夏威夷举行。ICCV是计算机视觉领域最具影响力的国际顶级会议之一,也是中国计算机学会(CCF)推荐的A类国际学术会议。该会议每两年举办一次,由美国电气和电子工程师学会(IEEE)与计算机视觉基金会(CVF)联合主办。
论文题目:High-Resolution Spatiotemporal Modeling with Global-Local State Space Models for Video-Based Human Pose Estimation
第一作者:封润洋(2022级博士研究生)
收录会议:ICCV 2025 (CCF-A类)
通讯作者:高一星
论文概述:
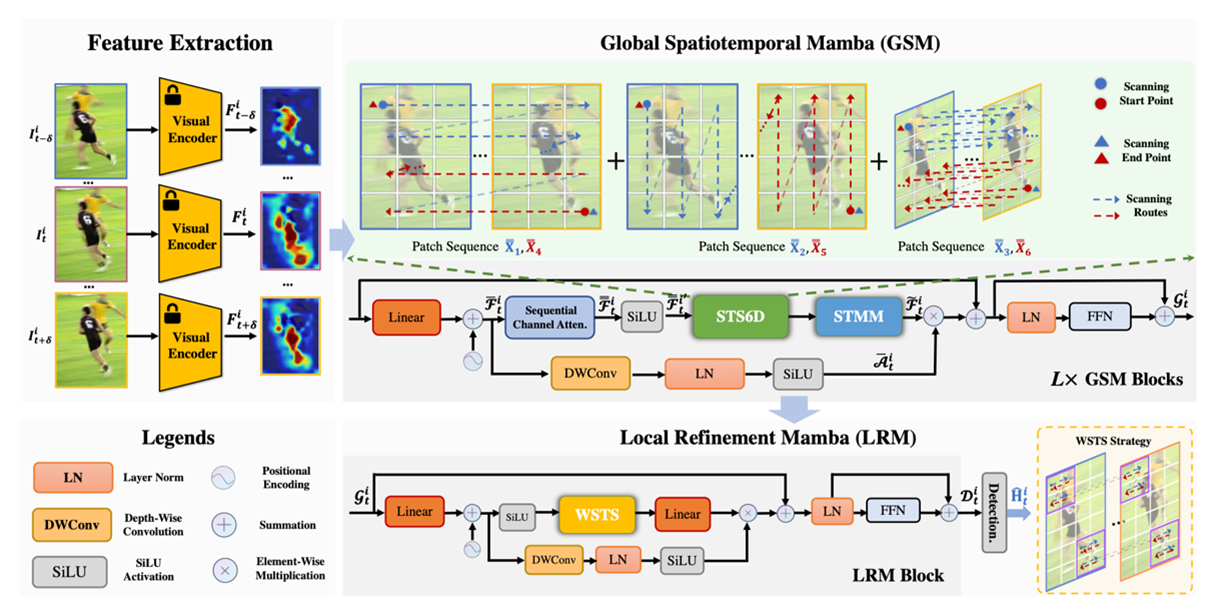
在基于视频的人体姿态估计任务中,建模高分辨率的时空表征至关重要。这不仅要求捕捉全局动态上下文(如整体的人体运动趋势),也需要刻画局部运动细节(如关键点的高频变化)。现有主流方法通常采用统一架构(如卷积或注意力模块)进行时空建模,难以兼顾全局与局部建模需求,往往会在两者之间产生偏倚,导致性能受限。此外,这类方法在建模全局依赖关系时存在二次复杂度且计算开销较大,限制了其实用性,特别在高分辨率视频中。近期,状态空间模型(State Space Models, SSM)如Mamba,在以线性复杂度建模长距离依赖方面表现出显著优势,但其主要适用于处理一维序列。为此,本文提出一种新颖框架,从两个方面扩展 Mamba,使其能够分别建模全局与局部的高分辨率时空表示,从而更高效地服务于视频人体姿态估计任务。具体而言,我们设计了全局时空 Mamba(Global Spatiotemporal Mamba,GSM),通过六向时空选择性扫描与时空调制的融合机制,有效提取高分辨率序列中的全局表示。进一步地,引入基于窗口化的时空扫描机制的局部优化 Mamba(Local Refinement Mamba, LRM),增强关键点局部运动的高频细节。在PoseTrack2017、PoseTrack2018、PoseTrack21以及Sub-JHMDB四个公开数据集上的广泛实验证明,所提出的方法在准确性与效率之间取得了更优平衡,显著优于当前主流基于视频的人体姿态估计方法。